Related Work
Diehl and Cook (2015)

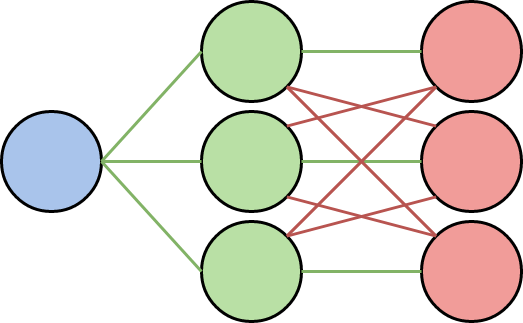
In this work, Peter U. Diehl and Matthew Cook, both from University of Zurich, proposed an unsupervised algorithm for training a spiking neural network on MNIST dataset, as depicted in the above figure. This network consists of three layers with the layers having the configuration as what follows:
| Layer | Input dimension | Output dimension |
|---|---|---|
| Input layer | 784 | Variable depending on the number of Neurons |
| Excitatory layer | Variable depending on the number of Neurons | Variable depending on the number of Neurons |
| Inhibitory layer | Variable depending on the number of Neurons | Variable depending on the number of Neurons |
In this network, we have excitatory layer neurons connected to only one neuron of the inhibitory layer each in a one-to-one fashion. On the other hand, the output of the neurons in the inhibitory layer are all connected to all the neurons of the excitatory layers except for the one it receives connection from. This way, other excitatory neurons get inhibited once an excitatory neuron spikes (An inhibitory neuron inhibits the internal voltage of a neuron once it receives some spike. This can be helpful in the sense that we can prevent the voltage of other neurons increasing). The membrain voltage threshold in this network changes adaptively once a neuron fires.
This way, This model is also different from Adaptive leaky integrate and fire in the way that although we are able to adapt the threshold voltage through training, because of the property mentioned above, only one excitatory neuron fires per input, which is also referred to as winner-take-all property.
The algorithm uses 4 different versions of STDP training. Also, it uses two rate encoding techniques through which it generates spikes in a way that they follow either Bernoulli and Poisson distribution. That way, the accuracy they achieved was around 95% which was the top among other unsupervised algorithms proposed before.
Deng et al. (2020)
This work applies a technique backpropagation algorithm. It does supervised training again on MNIST dataset. Its architecture consists of 3 layers with all the neurons following Leaky integrate and fire model. The accuracy achieved by applying this technique was 99.31%.